
AI in GRC: Where It Helps, Where It Hurts, and How I Built It
A follow-up to Building Your Own GRC Stack

Every GRC vendor has slapped “AI-powered” on their marketing. Most of it is window dressing.
The buzzwords are everywhere: AI-driven insights, intelligent automation, machine learning risk scoring. What’s missing is an honest answer to the question that matters: where does AI reduce pain versus create new problems?
After building AI into GigaChad GRC and watching practitioners use it, I’ve developed a framework I haven’t seen elsewhere. This post covers both philosophy and implementation.
Part 1: The Philosophy
The AI Hype Problem
Compliance has constraints most AI implementations ignore: auditability, explainability, accountability.
When an auditor asks “why did you rate this risk as high?”, the answer cannot be “the AI said so.” Regulators need evidence, not confidence scores from black boxes. Your board needs to understand methodology, not just trust an algorithm.
Most vendor AI optimizes for demos, not these realities.
AI that doesn’t help:
“AI-generated policies” with no traceability to requirements
Risk scores from black boxes auditors can’t explain
Chatbots hallucinating compliance requirements
Auto-classification with no override mechanism
The question isn’t “can AI do this?” It’s “should it, and how do we maintain control?”
Where AI Actually Helps
Patterns emerged from real usage. AI adds value in five categories—all sharing one property: AI handles toil while humans retain judgment.
1. Evidence Collection Automation
The sweet spot. Pull AWS configs, GitHub branch protection, Okta MFA status—mechanical tasks that previously required expensive integrations or manual screenshots. AI coordinates collection, not interpretation. Humans still decide if configurations meet requirements.
2. Questionnaire Response Drafting
Match incoming questions to your knowledge base, draft from previous answers. Critical: human always approves before sending. AI accelerates; it doesn’t decide. Prior responses are vetted, drafts are editable, the audit trail shows human approval.
3. Risk Categorization and Tagging
AI suggests categories, related controls, similar risks—with confidence scores. Low-confidence gets scrutiny; high-confidence can be batch-approved. Human confirms or overrides.
4. Report Generation
Synthesize control status into executive summaries, format evidence for auditors, summarize findings by severity. Synthesis, not judgment—underlying data remains the source of truth.
5. Smart Search
Natural language queries: “Show me encryption controls that failed testing last quarter.” AI translates intent into structured queries. Finding, not deciding.
Where AI Doesn’t Belong (Yet)
Autonomous control testing. “AI says we’re compliant” isn’t auditable. AI surfaces evidence; humans make pass/fail determinations.
Unsupervised policy creation. Policies encode organizational context. AI drafts; humans must review before publishing.
Risk acceptance decisions. Business judgment with accountability. AI quantifies; humans with authority decide.
Audit responses without review. One hallucination torpedoes an audit. Every character must be human-reviewed.
The Principle
AI should reduce toil, not replace judgment.
If an auditor asks “why did you do this?” and your answer is “the AI said so”—you’ve built a liability, not a tool.
Part 2: The Implementation
GigaChad GRC implements AI through Model Context Protocol (MCP) servers—keeping AI modular, optional, and auditable.
Why MCP?
MCP provides a standard way for AI tools to interact with external systems. Instead of embedding inference in your app, you expose tools that AI clients call.
This separation matters:
AI reasoning stays in the LLM. Models, prompts, conversation management—the client’s problem.
Domain logic stays in code. GRC knowledge, integrations, business rules in TypeScript, not prompts.
Works with multiple clients. Claude, Cursor, custom agents—any MCP client works.
Optional by design. Platform works without AI. Capabilities are additive.
The Architecture
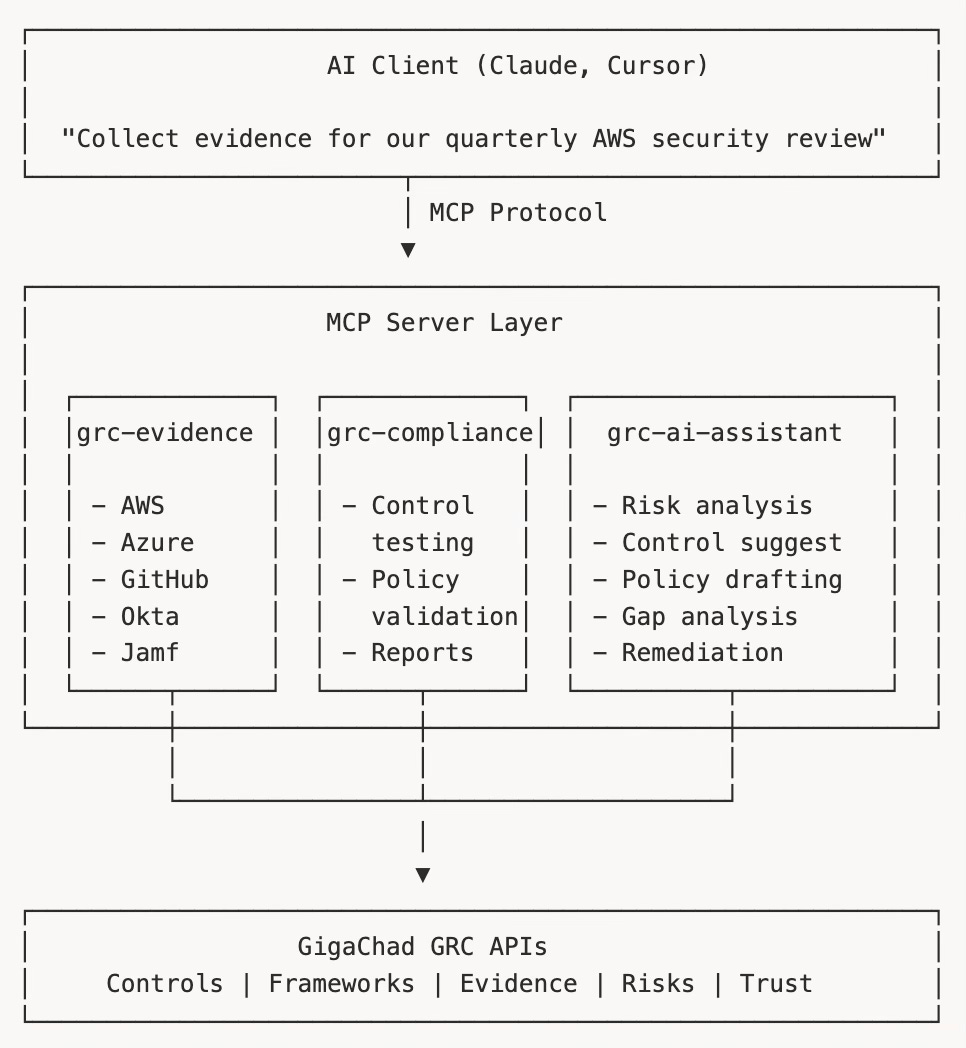
Three MCP servers, each with a distinct purpose:
grc-evidence: Automated Evidence Collection
This server handles the mechanical work of gathering compliance evidence from external systems. No AI inference required—just structured API calls to cloud providers and security tools.
Tools exposed:

Here's how a tool is defined:

When called, the tool handler collects structured evidence:

The output is structured JSON that gets uploaded to the evidence library. No interpretation—just facts about configuration state.
grc-compliance: Testing and Reporting
This server automates control testing and report generation. It runs predefined test procedures against collected evidence.
Tools exposed:

The control tester works with evidence to produce auditable results:

Test results include the evidence examined, criteria applied, and outcome—all auditable.
grc-ai-assistant: Intelligent Analysis
This server uses LLM inference for analysis tasks. Unlike the other servers, it calls AI models to generate insights.
Tools exposed:

The risk analyzer shows how AI suggestions are structured:

Every AI suggestion includes:
Scores with scales so humans understand the range
Rationale explaining why the AI reached this conclusion
Related items for context
Compliance impact tied to specific frameworks and controls
The rationale field is critical. It’s what you show the auditor when they ask “why?”
Building an MCP Server: The Pattern
If you want to add your own AI capabilities, here’s the pattern:
1. Project structure:

2. Server setup:

3. Connect to GigaChad GRC APIs:
Your tools can call the platform APIs to read and write data:

The Audit Trail Problem
Here’s the challenge: every AI-initiated action must be auditable.
When an AI tool collects evidence, we need to know:
What tool was called
What parameters were passed
What was returned
When it happened
Which AI session initiated it
The solution: audit logging middleware that wraps every tool call.

Evidence uploaded by AI is tagged with the collection method:

Auditors can filter to see all AI-collected evidence. Nothing is hidden.
Part 3: Practical Patterns
Three patterns emerged from production usage:
The “AI Suggests, Human Confirms” Pattern
Every AI output is a suggestion, not a decision.

Low-confidence suggestions (< 0.7) are flagged for detailed review. High-confidence suggestions (> 0.9) can be batch-approved. The threshold is configurable per organization.
The human sees:
What the AI suggests
How confident it is
Why it reached that conclusion
What alternatives exist
The human decides whether to accept, modify, or reject.
The “Evidence First, Analysis Second” Pattern
Never let AI analyze something you haven’t collected in structured form.
Wrong: “AI, tell me if we’re SOC 2 compliant.” Right: “Collect AWS configs, then show me the analysis.”
The evidence is the source of truth. AI explains evidence; it doesn’t replace it. Auditors can always drill down from the AI summary to the raw data.
The “Escape Hatch” Pattern
Every AI feature has a manual fallback.
AI evidence collection failing? Collect manually.
AI risk scoring seems wrong? Override it.
AI report generation broken? Export the data and build your own.
AI failures don’t block core workflows. The platform is fully functional without any AI server running.

Users can disable AI suggestions per module in settings. Some organizations disable AI entirely for regulated data. The platform respects that.
Closing: AI as Augmentation, Not Replacement
The best AI in GRC is invisible. It removes the tedious work—evidence collection, questionnaire drafting, report formatting—without inserting itself into decisions that require human judgment.
Here’s the test: can you explain every AI-influenced decision to an auditor using evidence they can verify? If yes, you’ve built AI that helps. If no, you’ve built a liability.
The MCP architecture keeps AI capabilities modular and optional. You can use all three servers, just one, or none. You can add your own. You can disable features that don’t fit your risk appetite.
Build for the auditor’s question: “Show me why you made this decision.”
If the answer involves evidence, human review, and documented rationale, you’re doing it right. If the answer is “the AI said so,” go back to the drawing board.
Get Involved
The MCP servers are in the repo:
mcp-servers/grc-evidencemcp-servers/grc-compliancemcp-servers/grc-ai-assistant
If you build new evidence collectors—for tools we haven’t covered yet—pull requests are welcome. If you’ve found ways to make AI more auditable in GRC, the community wants to hear about it.
The vendors will keep adding “AI-powered” to their marketing. We’ll keep building AI that actually helps practitioners.
The author still believes AI should reduce toil, not replace judgment. Still maintains the MCP servers. Still drinks too much coffee.